Two-dimensional t-SNE embedding of the representations in the last hidden layer assigned by DQN to game states experienced during a combination of human and agent play in Space Invaders.
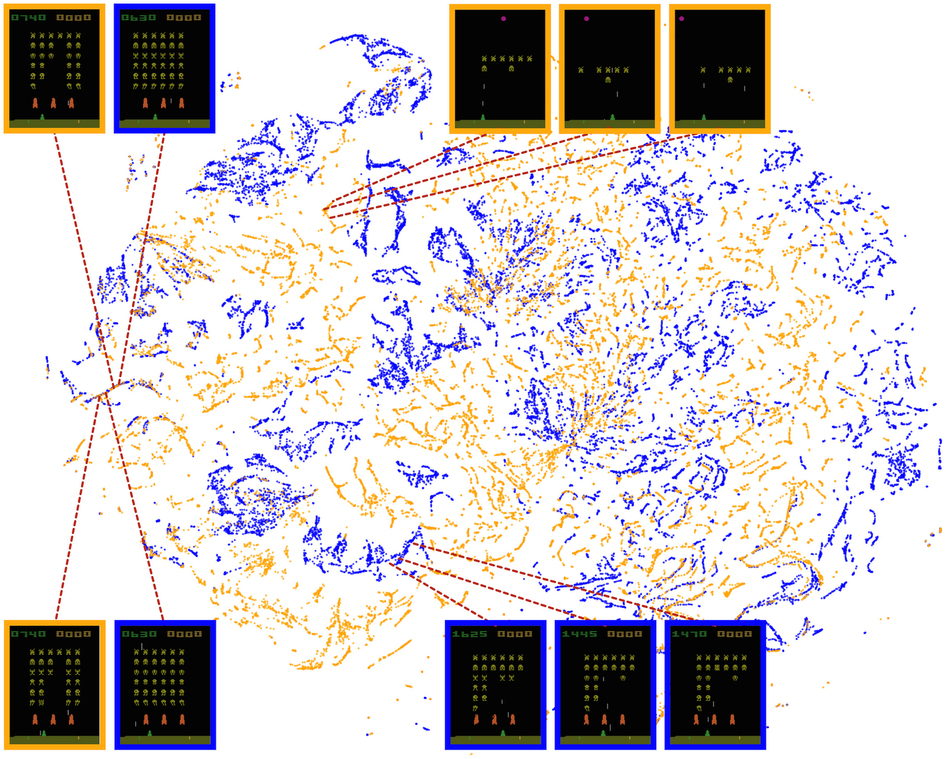
Two-dimensional t-SNE embedding of the representations in the last hidden layer assigned by DQN to game states experienced during a combination of human and agent play in Space Invaders.
Human-level control through deep reinforcement learning
by Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg and Demis Hassabis
Nature 518, 529–533 (26 February 2015)
http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html
The theory of reinforcement learning provides a normative account1, deeply rooted in psychological2 and neuroscientific3 perspectives on animal behaviour, of how agents may optimize their control of an environment. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task: they must derive efficient representations of the environment from high-dimensional sensory inputs, and use these to generalize past experience to new situations. Remarkably, humans and other animals seem to solve this problem through a harmonious combination of reinforcement learning and hierarchical sensory processing systems4, 5, the former evidenced by a wealth of neural data revealing notable parallels between the phasic signals emitted by dopaminergic neurons and temporal difference reinforcement learning algorithms3. While reinforcement learning agents have achieved some successes in a variety of domains6, 7, 8, their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces. Here we use recent advances in training deep neural networks9, 10, 11 to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning. We tested this agent on the challenging domain of classic Atari 2600 games12. We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to surpass the performance of all previous algorithms and achieve a level comparable to that of a professional human games tester across a set of 49 games, using the same algorithm, network architecture and hyperparameters. This work bridges the divide between high-dimensional sensory inputs and actions, resulting in the first artificial agent that is capable of learning to excel at a diverse array of challenging tasks.
Google network learns to play Space Invaders in breakthrough for artificial intelligence
The DQN network learned how to play classic video games including Space Invaders and Breakout without programming
by Sarah Knapton
The Telegraph
http://www.telegraph.co.uk/news/science/science-news/11435688/Google-network-learns-to-play-Space-Invaders-in-breakthrough-for-artificial-intelligence.html
By , Science Editor7:18PM GMT 25 Feb 2015 Comments33 Comments
Artificial intelligence has taken a major step forward after Google created a network which learned to play a range of computer games on its own without being pre-programmed.
The Deep Q Network (DQN) was given just the basic data from one Atari game and an algorithm which learned by trying out different scenarios to come up with the best score.
Without any further programming the network worked out how to play a further 48 classic video games including Space Invaders and Breakout.
Demis Hassabis of Google’s artificial intelligence arm DeepMind said the ultimate goal was to create a computer which had the mental capabilities of a toddler.
“This work is the first time that anyone has built a single general learning system that can learn directly from experience to learn a wide range of challenging tasks,” he said.
“In this case a set of Atari games and perform at better or human level on those fames
“DQN can learn to play dozens of the games straight out of the box. We don’t preprogramme it between its games.
“It has minimal sets of assumptions and all it gets access to are the raw pixel inputs and the game score and from there it has to figure out what it controls in the game world and how to get points and master the game just by playing the game directly.
“It’s the first artificial agent that is capable of learning to excel over a diverse array of challenging tasks.”
Mr Hassabis said the network was far superior to the computer Deep Blue which became the first machine to surpass humans when it beat chess grand master Garry Kasparov in 1997.
“With Deep Blue it was the team of chess grand masters which instilled the chess knowledge into a programme and that programme effectively executed that without adapting or learning anything,” he said.
“What we’ve done is build algorithms which learn from the ground up, so you give them perceptual experience and they learn how to do thinks directly.
“The idea is that these types of systems are more human like in the way they learn because that is how humans learn, by learning from, the world around us, using our senses, to allow us to make decisions and plans.”
Google programmers said they had been amazed with some of the solutions that the network had come up with for winning the game, such as keeping the submarine just below water level in SeaQuest to stay alive and creating a tunnel in Breakout so that the ball passed through and could hit more bricks.
The company is currently in talks with meterological and financial companies to use the algorithm for weather prediction or to predict the stock market.
“One of the things we’re trying to do we’re trying to build the ability of two or three year toddler, pre-linguistic toddler and we aren’t anywhere close to that. B
“But this is as good as a professional human game tester.”
The research was published in the journal Nature.