The Four V’s of Big Data
・ Volume (Scale of data; 大きなデータ)
・ Velocity (Speed of data; 速く処理されるデータ)
・ Variety (Diversity of data; バラバラなデータ)
・ Veracity (Certainty of data; 不確かなデータ)
Srinath Perera https://kushima38.kagoyacloud.com/?p=57578
Big data established the value of insights derived from processing data. Such insights are not all created equal. Some insights are more valuable shortly after it has happened with the value diminishes very fast with time. Stream Processing enables such scenarios, providing insights faster, often within milliseconds to seconds from the trigger.
_________________________________________________
Variety (Diversity of data; バラバラなデータ)
**
NHK https://kushima38.kagoyacloud.com/?p=57569
厚生労働省がデータベースに蓄積している診療報酬明細書のおよそ58億件のデータのおよそ80%が、特定健診のデータと突合できず、糖尿病など生活習慣病の対策に活用できなくなっている。名前のデータが健診ではかたかなだったのに、明細書では漢字だったことなどから、暗号化する際、違う記号になった可能性がある。
_________________________________________________
Veracity (Certainty of data; 不確かなデータ)
**
Kevin Fink https://kushima38.kagoyacloud.com/?p=57572
It is not uncommon to be handed a dataset without a lot of information as to where it came from, how it was collected, what the fields mean, and so on. In fact, it’s probably more common to receive data in this way than not. In many cases, the data has gone through many hands and multiple transformations since it was gathered, and nobody really knows what it all means anymore.
**
Bruce Ratner https://kushima38.kagoyacloud.com/?p=57576
The regression theoretical foundation and the tool of significance testing employed on big data are without statistical binding force. Thus, fitting big data to a prespecified small-framed model produces a skewed model with doubtful interpretability and questionable results.
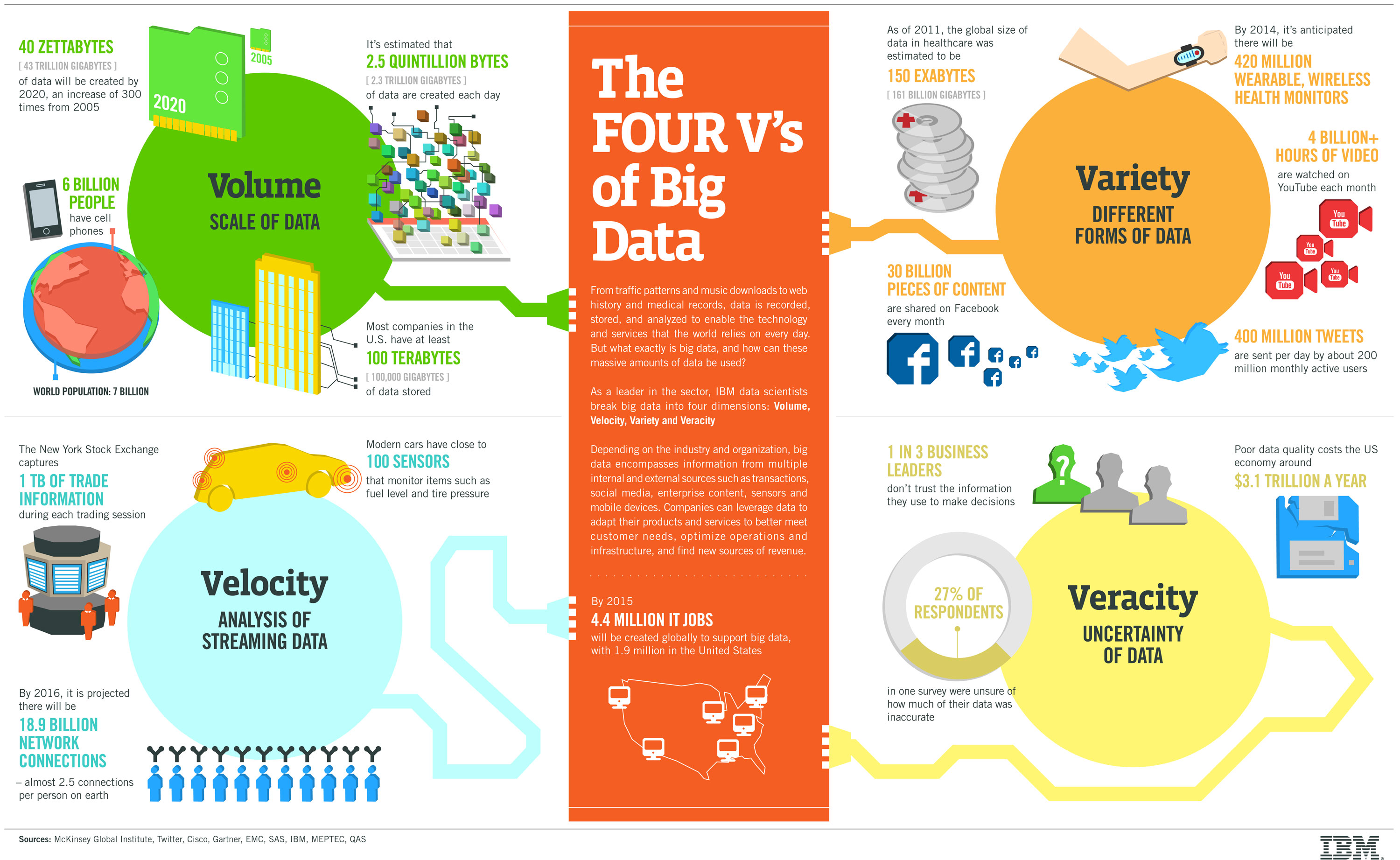
The Four V’s of Big Data
IBM
https://www.ibmbigdatahub.com/infographic/four-vs-big-data
The Four V’s of Big Data
・ Volume (Scale of data)
・ Velocity (Speed of data)
・ Variety (Diversity of data)
・ Veracity (Certainty of data)
The Fifth “V”
・ Value
Extracting business value from the 4 V’s of big data
IBM
https://www.ibmbigdatahub.com/infographic/extracting-business-value-4-vs-big-data
The Four V’s of Big Data
・ Volume (Scale of data; 大きなデータ)
・ Velocity (Speed of data; 速く処理されるデータ)
・ Variety (Diversity of data; バラバラなデータ)
・ Veracity (Certainty of data; 不確かなデータ)
_________________________________________________
Volume (Scale of data; 大きなデータ)
**
永安悟史
https://kushima38.kagoyacloud.com/?p=57580
「Volume」への対応力はテクノロジーの進歩とともに非常に高まってきたと思います。私自身、現在はExadataのユーザですし、周りにはHadoopユーザも多くいますが、数千万、億単位のレコードのテーブルを処理するのは当たり前、というような日々になりつつあります。一昔前と比べると大容量のデータを処理するテクノロジーは大きく発達して、身近に、かつ使いやすくなってきました。
_________________________________________________
Velocity (Speed of data; 速く処理されるデータ)
**
Srinath Perera
https://kushima38.kagoyacloud.com/?p=57578
Big data established the value of insights derived from processing data. Such insights are not all created equal. Some insights are more valuable shortly after it has happened with the value diminishes very fast with time. Stream Processing enables such scenarios, providing insights faster, often within milliseconds to seconds from the trigger.
_________________________________________________
Variety (Diversity of data; バラバラなデータ)
**
NHK
https://kushima38.kagoyacloud.com/?p=57569
厚生労働省がデータベースに蓄積している診療報酬明細書のおよそ58億件のデータのおよそ80%が、特定健診のデータと突合できず、糖尿病など生活習慣病の対策に活用できなくなっている。名前のデータが健診ではかたかなだったのに、明細書では漢字だったことなどから、暗号化する際、違う記号になった可能性がある。
_________________________________________________
Veracity (Certainty of data; 不確かなデータ)
**
Kevin Fink
https://kushima38.kagoyacloud.com/?p=57572
It is not uncommon to be handed a dataset without a lot of information as to where it came from, how it was collected, what the fields mean, and so on. In fact, it’s probably more common to receive data in this way than not. In many cases, the data has gone through many hands and multiple transformations since it was gathered, and nobody really knows what it all means anymore.
**
Bruce Ratner
https://kushima38.kagoyacloud.com/?p=57576
The regression theoretical foundation and the tool of significance testing employed on big data are without statistical binding force. Thus, fitting big data to a prespecified small-framed model produces a skewed model with doubtful interpretability and questionable results.