 While the information used us input to an activity or process is likely to be found in the left part of the Long Tail power graph, the information needed for a knowledge work activity is likely to be found in the long tail. There you have information resources which are used infrequently or maybe even once. The information which is needed varies from time to time, from situation to situation. Not only the actual information varies; often the type and structure of the information resource varies too. This makes it virtually impossible to define a reusable information resource in advance before it is needed.
While the information used us input to an activity or process is likely to be found in the left part of the Long Tail power graph, the information needed for a knowledge work activity is likely to be found in the long tail. There you have information resources which are used infrequently or maybe even once. The information which is needed varies from time to time, from situation to situation. Not only the actual information varies; often the type and structure of the information resource varies too. This makes it virtually impossible to define a reusable information resource in advance before it is needed.
Why traditional intranets fail today’s knowledge workers
by Oscar Berg
http://www.oscarberg.net/2010/07/serving-long-tail-of-information-needs.html
There’s a long tail of information needs that still needs to be served
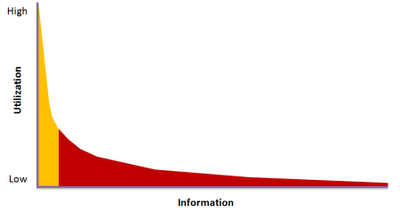
Assuming we have a long tail of diverse, constantly changing and virtually unlimited amount of information needs, we need to do what can be done to serve these needs in some way or another. The problem is that the information resources that most businesses choose to produce and provide access are not aimed at serving these infrequent, uncertain and constantly changing information needs. Let’s use the Long Tail power graph above to illustrate and further expand this reasoning.
In the left end of the power graph we have the information resources which are most frequently used because they are serving frequently recurring information needs. The information which is needed for transformational and transactional activities – but also administrative knowledge work – is likely to be served by information resources in the left part of the Long Tail power graph. This information does not change very often and thus can be quite easily reused. It’s the kind of information used for commonly performed activities, which means that the information needs are predictable. An information need that has occurred once will for certain occur again. This allows us to define, design and produce the type and structure of the information as well as the actual information before the next time the information need arises (the activity is performed).
Knowledge work is often a completely different story. While the information used us input to an activity or process is likely to be found in the left part of the Long Tail power graph, the information needed for a knowledge work activity is likely to be found in the long tail. There you have information resources which are used infrequently or maybe even once. The information which is needed varies from time to time, from situation to situation. Not only the actual information varies; often the type and structure of the information resource varies too. This makes it virtually impossible to define a reusable information resource in advance before it is needed.
The unpredictable nature of knowledge work is why we need to give knowledge workers access to all information that exists and that might be relevant. Since we don’t know what might be relevant until a certain need arises (which we never might be aware of until we discover certain information), we can’t really put the relevant information in one “for keeps” pile and all other information in another “to be trashed” pile. We also need to provide them with tools so they can create or capture information with each other, or else there will not be enough information available to serve the knowledge workers’ information needs. To help people find and discover information that is relevant to their tasks when they need it, we also need to create powerful pull mechanisms which allow relevant information to automatically surface and be placed at the fingertips of knowledge workers just when they need it.
Traditional intranets are not designed for knowledge work
This leads me to the changing role of intranets in knowledge-intensive businesses. These intranets need to provide flexible access to both information and people by employing pull models for serving as many knowledge worker information needs as possible, including unanticipated information needs. Information supply needs to be maximized by supporting the creation and access to user-generated content as well as by allowing for easy integration of external information sources. The intranet needs to be turned into an “information broker platform” where information is freely and easily created, aggregated, shared, found and discovered at minimal effort. Such an intranet gives everybody access to all information which is available and make room for virtually infinite amounts of information.
However, most of today’s intranets primarily consist of pre-produced information resources which are intended to serve information needs which can be anticipated in advance. They aim to serve people who perform predefined and repeatable tasks. These intranets are push platforms. As such they might work well for repeatable routine work where the information needs can be defined in advanced, but they are quite dysfunctional for knowledge work. It’s not a coincidence that many knowledge workers find it much easier to find information on the web than in their internal systems and that the intranet plays a marginal role in their daily work.
The information that knowledge workers need can often not be anticipated and served by a push-based intranet. It is also critical that they have access to ALL information that is available, including collaborative content produced by teams, content produced by external resources, tacit knowledge captured in conversations, and so forth. Since the information artifacts on an intranet typically are produced by a relatively small part of the organization’s total workforce, the resources available for producing these information resources are limited. A line needs to be drawn between information needs which can be served and those which cannot be served. A common approach is to identify the most common information needs and focus available resources on serving these needs as good as possible. Assuming that the resources for producing and maintaining information resources are scarce, this is a seemingly feasible approach. But it’s not a feasible approach for an intranet that needs to serve the highly varying, extensive and unpredictable information needs of knowledge workers.
To conclude: a major reason why traditional intranets fail today’s knowledge workers is that all information they provide access to is produced with a push-based production model. This model assumes that all information resources on the intranet must be produced in advance (only serving information needs which can be anticipated) by a small subset of all available resources (employees) and that the entire body of information needs to be supervised by a few people for the purpose of controlling the message, format and/or organization of the information resources.